免费 1500 次背后,商汤在下一盘什么棋
作者|Cynthia
编辑| 郑玄
商汤最近做了一件大多数大模型公司都不舍得做的事。
每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。
免费从来不是目的。问题是,它图什么?答案,是一套从模型、工具链到生态锁定的三层护城河。
如果要给过去三年的大模型行业挑个刺,人肉胶水一定排得上号。
一方面,模型能力越来越强,编程、问答、推理、绘画,单点拿出来都是专家水平。但问题也跟着来了,这些 SOTA 级的能力,本质上还是一座座互不相通的孤岛。
在内容创作、设计创意、编程等工作中,AI 负责了最有创意的环节,却把图文整合、校对、排版、内容搬运这些脏活,留给了人类。技术提升带来的效率红利,有相当一部分被胶水成本吃掉了。
那么,能不能把完整方案生成变成模型内置能力?商汤的回答是:不光能,而且免费。
就在前几天,商汤一举推出了三个具备完整交付能力的产品与模型:
SenseNova 6.7 Flash-Lite :新一代多模态智能体模型,具备顶尖的 Agent 能力,为复杂数据分析与任务规划而生,能很好适配高频、高并发的生产级办公需求。
SenseNova U1 :基于自研的 NEO-unify 原生理解生成统一架构,首创连续图文创作输出,实现复杂信息图生成。
全线办公技能 SenseNova-Skills :支持海量数据分析、自动化办公等实战场景。
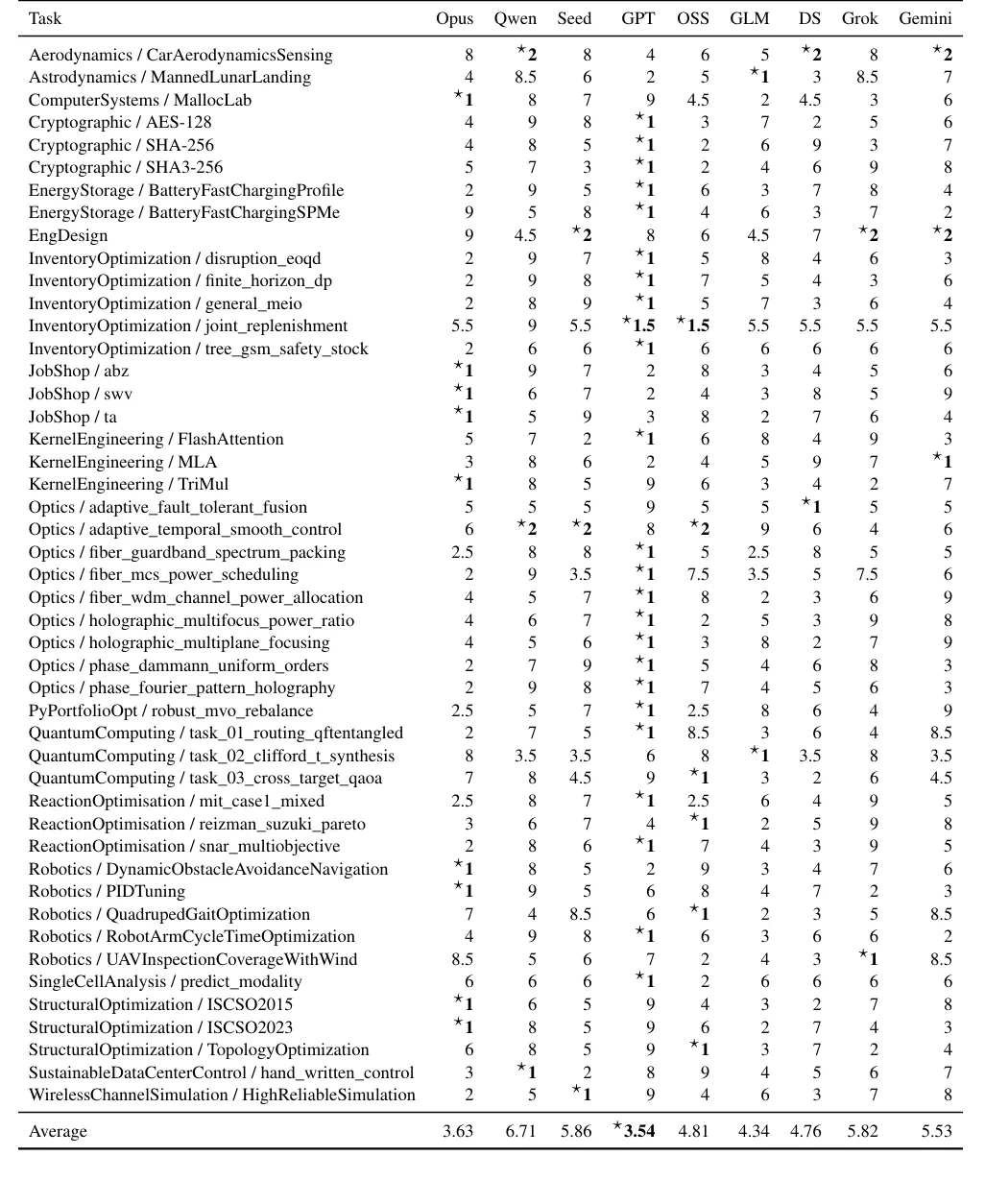
而伴随着产品上线,商汤还推出了 SenseNova Token Plan,赠送首月每 5 小时 1500 次免费调用额度 ,不可谓不豪横。
要理解这套打法背后的逻辑,先从护城河的第一层说起。
01
第一层护城河:做别人做不到的事
SeneNova U1:从「会画画」到「会思考再画画」,差距在哪里?
先聊几个数字。
U1 于 4 月 28 日正式发布,两个版本的模型权重(SenseNova-U1-8B-MoT 和 SenseNova-U1-A3B-MoT)均采用 Apache 2.0 协议开源,支持商业使用和本地部署。发布后迅速在 Hugging Face 收获大量开发者关注,成功冲进 Trending 榜前列。这个热度,在最近扎堆发布的开源多模态模型里,实属少见。
它凭什么?答案在架构里。
商汤 SenseNova U1 技术报告认为,多模态智能不应只是把视觉编码器、语言模型和图像生成器拼接起来,而应在同一表示空间中同时完成”看、读、想、画”。 这是 U1 系列模型的核心技术理念,也是 NEO-Unify 架构的出发点。
传统多模态模型的架构,是视觉编码器 (VE) + 变分自编码器 (VAE) 的组合——用 VE 做理解、用 VAE/扩散潜空间做生成。看图和画画是两套独立系统,模态转换过程会带来信息丢失,表示空间也是割裂的。
NEO-Unify 的做法截然不同:直接在像素 patch 与文本 token 上端到端建模,统一支持视觉理解、图像生成、图像编辑、交错图文生成等任务。理解和生成不再是上下游模块,而是同一上下文中的两种推理视角。
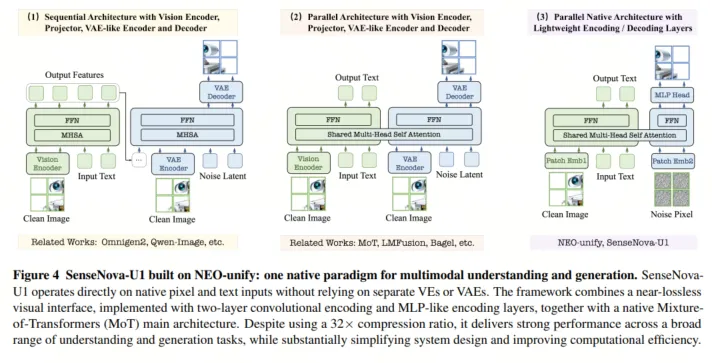
具体到架构设计上,NEO-Unify 同时解决了三组长期存在的矛盾:
第一,近无损视觉接口。 输入端不用 CLIP、SigLIP 等预训练视觉编码器,而用两层卷积加 GELU 将图像转为 token;输出端不用 VAE decoder,而用两层 MLP 直接预测原始像素 patch。表示空间由模型自身学习,既能承载高层语义,也保留生成所需的局部纹理、文字边缘和结构细节。
第二,分辨率自适应 flow matching。 动态分辨率会导致固定噪声先验在不同尺度下信噪比不一致,U1 引入分辨率自适应噪声尺度,使 256 到 2048 等不同分辨率下的像素空间生成更稳定。
第三,原生 Mixture-of-Transformers(MoT)。 理解流与生成流共享 self-attention 上下文,但 Q/K/V/O、LayerNorm、MLP 等参数解耦;文本、理解图像 token、生成图像 token 在每层交互,却保留各自表征专长。同时,三维 RoPE 把 token 放入时间、高度、宽度三轴坐标,从位置编码层面统一了语言顺序与二维结构。
这套机制的关键价值在于:MoT 的参数解耦加共享注意力上下文,能降低理解与生成之间的内在冲突。消融实验也证实了这一点——即使生成数据和理解数据共同训练,理解能力仍保持稳定,生成能力反而收敛更快。统一架构不是折中,而是带来了真正的跨能力协同。
这不只是架构描述, 有数据为证: 即便是 2B 参数量的 NEO-Unify 模型,在图像重建基准 MS COCO 2017 上,也达到了 31.56 PSNR、0.85 SSIM 的成绩,与公认的业界标杆 Flux VAE(32.65 PSNR、0.91 SSIM)差距不足 1 个百分点——而 Flux VAE 是一个专门为生成优化的独立组件,U1 是用一个统一架构顺带完成的。更值得关注的是,与同类统一模型 BAGEL 相比,NEO-Unify 在更少的训练 token 下取得了更好的表现,数据效率的优势相当显著。
实测效果如何?
技术报告显示,在基准测试中 SenseNova U1 展现出均衡且出色的能力谱系。多模态理解上,A3B-MoT 在 MMMU 达 80.55、MMMU-Pro 达 72.83,OCRBench 达 91.90,说明文本密集图像和通用视觉理解没有因统一生成而削弱。生成方面,GenEval 总分约 0.91-0.92,组合、计数、颜色、位置和属性绑定稳定;OneIG 英/中文文本维度最高达 0.969/0.977,LongText-Bench 英/中文达 0.979/0.962,长文本渲染能力尤为突出。
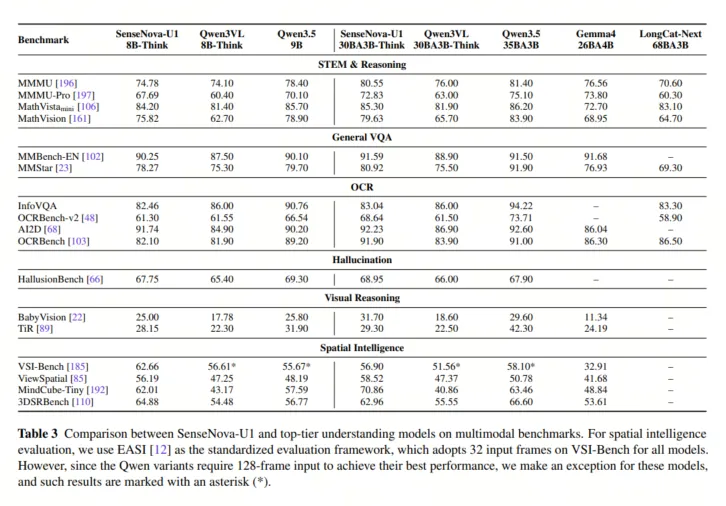
SenseNova-U1 与其他顶级多模态理解模型在多模态基准测试(Benchmarks)
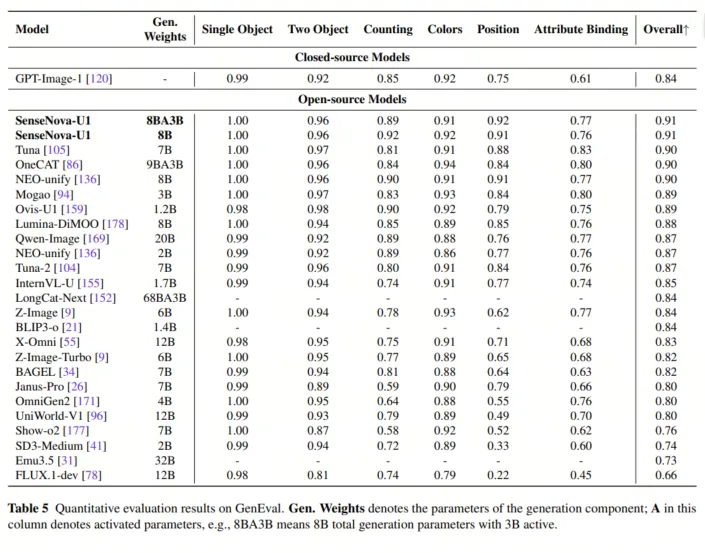
GenEval 上的定量评估结果
在图文交错生成(OneIG 中英文、LongText 中英文、CVTG)和信息图专项(BizGenEval Easy/Hard、IGenBench)的延迟-性能综合对比里,U1 在同等延迟区间内综合表现领先 Nano-Banana、Gemma-4 等主流开源模型,是目前开源模型里的 SOTA 水平。在与商业闭源模型的横向对比中,U1 Lite 在通用图像生成上的输出质量已与 Qwen-Image 2.0 Pro、Seedream 4.5 持平;在信息图这个历来是开源模型”滑铁卢”的领域,同样达到了商业级水准。
举个例子,输入「帮我生成一道做炒野生菌的教程」。完整的图文混排内容,就在十几秒时间里完整处理好了。它能在多轮推理过程中,边进行逻辑推导,写文字并输出食材、数量、配料、火候,动作对应的草图,再利用这些自行生成的视觉内容继续辅助后续推理,生成图文并茂的完整教程。

生成信息图也是一句话的事。比如,让它生成极简风的大自然碳循环图。整张图里的自然界碳循环逻辑完全正确,没有信息遗漏。在信息呈现上,以模块化区分不同功能模块,用符号化的视觉元素替代纯文字表述,既保留了有机物化学式、碳酸盐等专业细节,又通过自然系配色与具象化场景降低了大众认知门槛。从信息准确度、视觉层级、专业细节保留三个维度来看,是一张相当成熟的科普可视化作品。
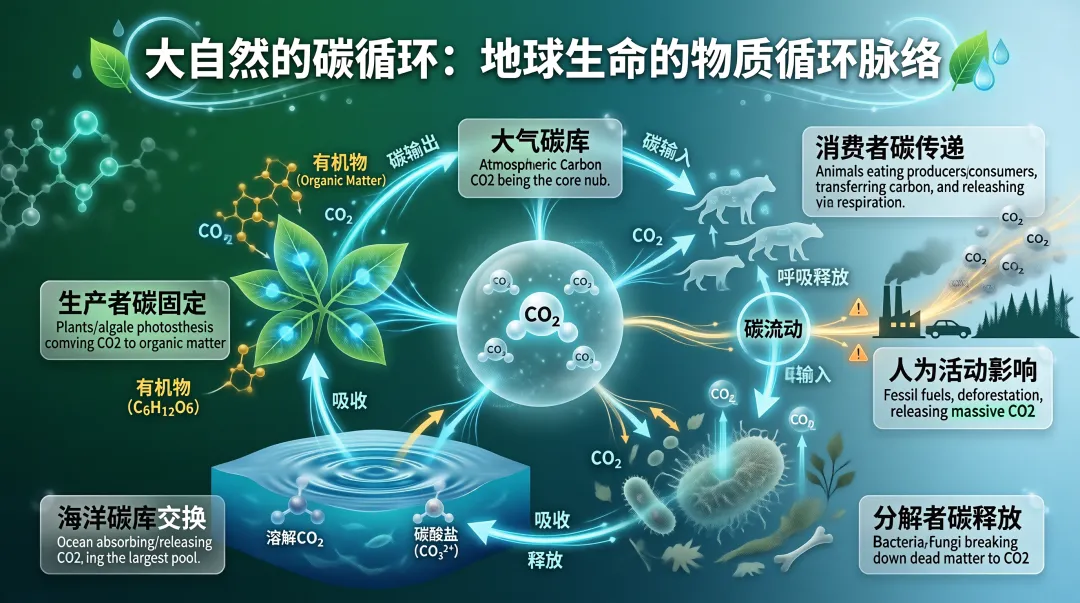
过去,AI 无法做到的根本原因在于,类似的内容产出不仅是画得好,更需要排版美、信息准确、逻辑清晰、字体统一,是多个能力的综合考验。传统的分步生成再拼接模式,一个环节做到 90 分,连续经过五个环节,生成的就是一个只有 59 分的残次品。
U1 系列模型,通过将理解、推理、生成统一为一个整体,首次让 AI 交付一个及格线上的完整结果成为了可能。这正是去掉了创意端最厚的那层人肉胶水。
02
第二层护城河:低成本把人留住
SenseNova 6.7 Flash-Lite:当 AI 能真正看懂文档,工作流效率翻几倍?
U1 更像一个多才多艺的创作者,而 SenseNova 6.7 Flash-Lite 更像一个能管理全局的项目经理。
如果说 U1 解决的是创意端的闭环问题,那 SenseNova 6.7 Flash-Lite 解决的则是完整工作流的问题。它专门为真实世界工作流而生,能稳定支撑数据分析、深度调研、复杂图片理解、PPT 生成这些长链路办公任务。能力上,它原生支持 OpenClaw、Hermes Agent 等智能体框架,配合 SenseNova-Skills,可以一键开启全自动办公
传统智能体模型采用语言+视觉拼接设计,视觉只是文本的补充,无法深度参与核心决策与推理循环。信息在转译过程中受损,也会导致 Token 消耗虚高。
6.7 Flash-Lite 不一样。它能直接看懂复杂的网页布局、文档结构、财务图表,实现看、想、做一体化。借助这种真正的「看懂」,6.7 Flash-Lite 也做到了 Token 消耗直降 60%——在信息搜索等场景,对比纯文本智能体,这个节省幅度相当可观。
这正是第二层护城河的核心: 让用户用得更便宜,便宜到不值得换一个平台。
一个案例。给它一段 36 个月、近 90 万行销售记录的数据,让它完成完整的企业运营分析报告。
模型没有直接跳入统计,而是先进行数据审计,敏锐地察觉到单价中的异常离群值,判断这些极值对应了促销或高端单品场景,予以保留以反映真实市场波动。 这是模型主动发现的问题,而非用户指定分析方向——这才是真正的亮点所在。
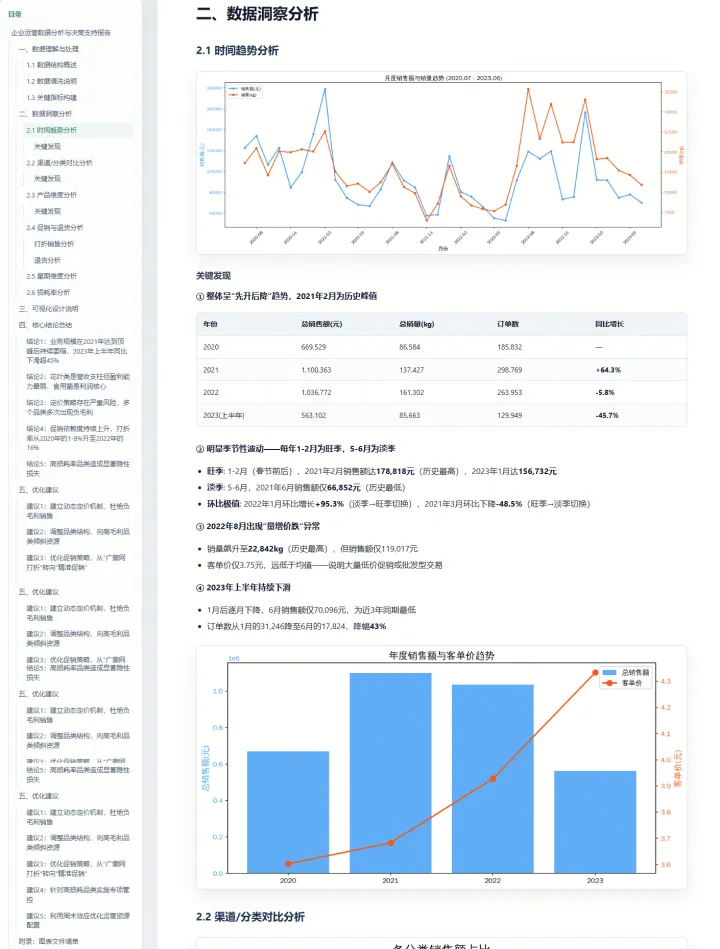
分析毛利时发现辣椒类 2022 年 5 月出现严重负毛利,进一步探寻供应链环节,诊断出采购成本控制与零售定价间缺乏联动机制的问题,并主动提出了五项精准建议:建立动态定价机制、调整品类结构等,直接辅助管理层决策。

当然,6.7 Flash-Lite 的能力远远不止是分析数据。
数据分析之外,6.7 Flash-Lite 还能直接生成 PPT。从叙事逻辑到版面设计全自动产出,风格统一、元素对齐,生成即交付。从数据分析到内容呈现,中间不再需要人来搬运——这正是去掉了交付端最后一层人肉胶水。
03
第三层护城河:工具链让人走不掉
大模型公司的竞争,已经从模型能力蔓延到了生态与场景。
当 GPT 和 Claude 的能力差距已经从代际碾压变成各有千秋,开源模型的能力已经不断逼近闭源 SOTA 水平,单靠模型性能已经很难形成持续的竞争优势。这时候,谁能让用户用得更省心、更便宜、更完整,谁就能在激烈的竞争中脱颖而出。
商汤的 SenseNova 体系,正是新规则下的代表性玩家。
要理解这套生态的锁定逻辑,可以借用一个经典的商业模型:剃须刀与刀片。
免费或低价提供剃须刀(模型和调用额度),通过持续消耗刀片(工具链使用量和规模化付费)来盈利。商汤的三层护城河,本质上都是在服务这一个飞轮。
模型差异化, 是让人愿意第一次进来。NEO-Unify 架构让 U1 在信息图生成、图文交错、多步推理上做出了真正的差异——技术报告中的消融实验也证实,这种统一不是能力折中,而是带来了理解与生成的双向协同增益,是竞争对手短期内难以复制的技术壁垒。
低成本 Token 输出, 是让人不舍得走。首月每 5 小时 1500 次的免费额度,加上长期比同行低 60% 的 Token 消耗,把试错成本压到最低。Apache 2.0 的开源协议,进一步消除了开发者进入的心理门槛。
值得一提的是,U1 的推理系统并非停留在论文结构:LightLLM 负责多模态理解与请求调度,LightX2V 负责图像生成,两者通过共享内存和优化传输 kernel 交换状态,FlashAttention3 后端在统一多模态 prefill 中相比 Triton 有约 2.3 到 3.2 倍的加速——正是这套可服务、可扩展的基础设施,才撑起了低成本大规模商用的底气。
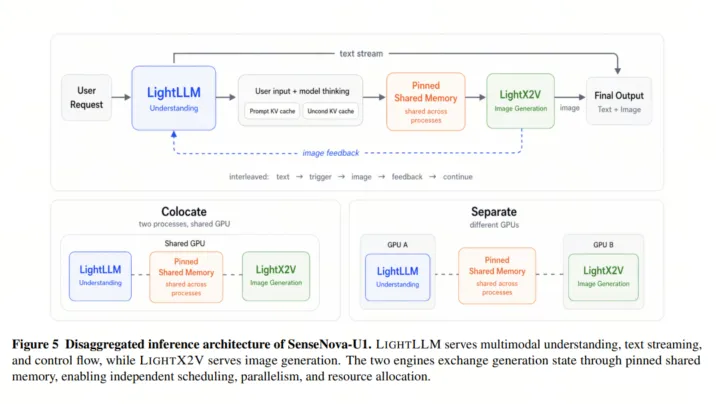
工具链的完整性, 是让人真的走不掉。商汤的生态不只有模型,还包括:
SenseNova-Skills:覆盖信息图生成、PPT 创作、数据分析、深度调研等高频办公场景
Agent Pack:集成了 Hermes Agent 和 OpenClaw 框架的一键部署包
结合起来,当开发者因为低成本开始尝试商汤的工具链,会逐渐被工具链以及交付产品的完整性所吸引;当他们习惯了整套工作流的协作效率,换平台的迁移成本就会变得极高;当这种使用习惯扩散到整个团队,商汤就拥有了用户粘性带来的持续付费。
这套闭环一旦形成,就会在开发者生态中产生网络效应:用的人越多,贡献的反馈和案例越多,模型迭代的方向就越精准,工具链的打磨就越完善,Token Plan 的成本摊薄效应就越明显。
当然,这一飞轮要真正转起来,前提是商汤能在竞争激烈的窗口期内迅速积累足够的用户基数。DeepSeek、Qwen、InternVL 们都在同一条赛道上全力冲刺,这场仗远没有结束。
但至少眼下,商汤给出了一个值得认真对待的答案:用一套从架构创新(NEO-Unify)到工具闭环(SenseNova-Skills)再到成本优势(Token Plan)的完整体系,把”去人肉胶水”从一句口号,变成了可交付的产品。
技术报告的结论说得直接: 多模态智能的未来突破,并不只是简单的规模扩大,更重要的是朝着深度融合进化的内核架构创新。这句话,也许正是商汤这盘棋真正的谜底。
对于开发者和企业来说,现在正是低成本进入这套生态、验证其价值的最佳窗口期。
大模型的竞争里,技术领先只是起点,生态锁定才是终点。
SenseNova U1:
https://github.com/OpenSenseNova/SenseNova-U1/
SenseNova-Skills:
https://github.com/OpenSenseNova/SenseNova-Skills
TokenPlan 免费领取:
https://sensenova.sensetime.com/
*头图来源:商汤科技
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO